Complex Projects,
Not Processes
Core 2 is a modular framework with a data-centric approach, designed to help businesses harness the growing complexities of real-time deployment and monitoring.
Book a Demo
Discuss your ML use cases and challenges with an expert for a tailored deep dive into how Seldon can support your goals.
Book a Demo
Trusted by the Worlds Most Innovative ML and AI Teams

9.5+
Million models installed across a range of model types from the most popular libraries to custom developments
4.8
GitHub rating and trusted by ML and AI teams worldwide for better machine learning deployment and monitoring
85%
Increase in productivity through enablement of better workflows and more efficient use of resources
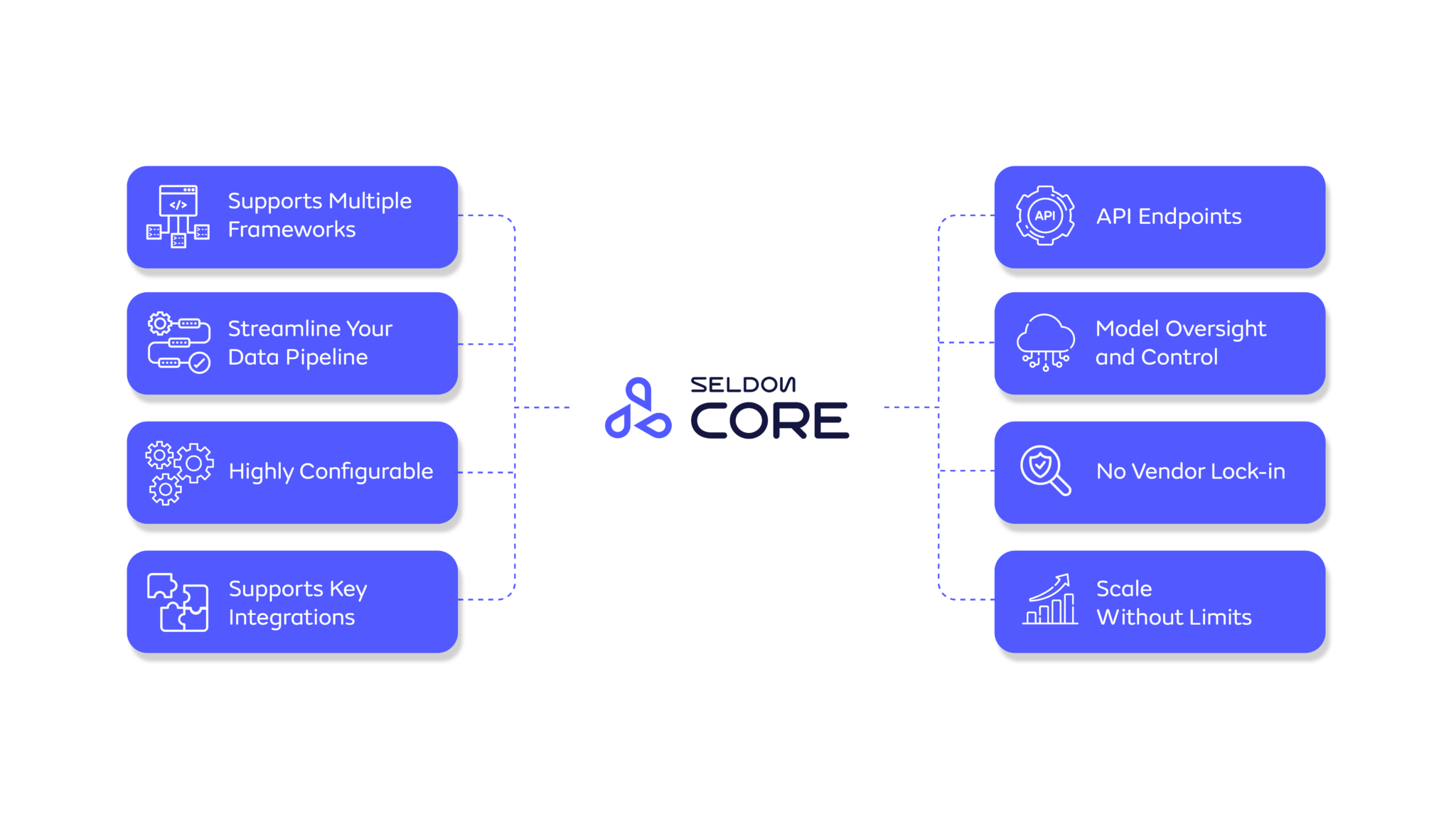
Core 2 is built to put models into production at scale, especially for data-critical, real-time use cases (e.g., search, fraud, recommendations)
Freedom to Innovate Without Restrictions
Seldon offers a platform- and integration-agnostic framework, enabling seamless on-premise or cloud deployments for any model or purpose regardless of your tech stack requirements.
Support Multiple Runtimes
Benefit from a broad range of pre-trained models, including Triton via ONNX, PyTorch, TensorFlow, and TensorRT, MLFlow, Scikit, XGBoost, Hugging Face, and custom.
Seamless Integrations
Connect with CI/CD, automation, and various ML tools (cloud, in-house, third-party).
Flexible, Standardized Deployment
Deploy anywhere across cloud, hybrid, or on-prem. Run ML, custom models, or GenAI with one workflow. Mix and match runtimes, from custom to out-of-the-box.
Streamlined Operations
No tireless search for models and information while creating more opportunity to scale with less overhead, and reduces risk of investment with the ability to identify problems and opportunity faster with features like:
Standardized Inference Protocol
Supports only model servers following the Open API Inference Protocol for consistent request and response handling.
Built-in Model Servers
Includes MLServer and Triton to support all major ML frameworks, with easy customization for input/output handling.
Manifest-Based Configuration
Manage models and workflows with a simple file, avoiding the complexity of function-based coding.
Optimized Autoscaling
Standardized CPU utilization metrics enable seamless scaling across models, eliminating hardware-specific dependencies.
Enables Enhanced Observability
Enables visibility into ML systems, covering data pipelines, models, and deployments through features like:
Real-Time Insights & Streaming
Stream and store efficiently. Track and audit models with full transparency into data and decisions.
Exposed, Flexible Metrics
Aggregate operational, data science, and custom metrics for tailored insights.
Interconnected Inference Logic
Enable richer, more dynamic insights by ensuring inference logic seamlessly connects across modules.
Programmatic Inference Graph
Define component relationships, create manifest files, and connect multiple components in a single manifest.
Modular Framework for More Optimized Infrastructure
Dynamically adjust infrastructure based on actual demand, minimizing waste, reducing costs, and optimizing performance with features like:
Experimentation-Driven Efficiency
Improve model quality while optimizing cost and resources through experimentation features.
Interconnected Inference Logic
Ensures data flows seamlessly across modules for richer, dynamic insights.
Separation of Concerns
Data-centric architecture maintains modular independence, simplifying updates and scalability.
Smart Scaling & Autoscaling
Scale models and servers based on workload demand, with adaptive batching in MLServer for fine-tuned efficiency.
Multi-Model Serving (MMS)
Deploy multiple models efficiently on fewer servers, optimizing infrastructure and costs.
Overcommit for Smarter Memory Use
Uses an LRU caching mechanism to prioritize frequently accessed models, reducing memory constraints and enabling large-scale deployments.
Get to Know Core 2
Seldon Core 2 was developed to put data at the center of your machine learning deployments for more enhanced observability leading to better understanding, trust, and iteration of current and future projects.
+Support and Modules
Our business is your success. Stay ahead with accelerator programs, certifications, hands-on support with our in-house experts for maximum innovation.

Accelerator Programs
Tailored recommendations to optimize, improve, and scale through bespoke, data-driven suggestions.

Hands-on Support
A dedicated Success Manager who can support your team from integration to innovation.

SLAs
Don't wait for answers with clear SLAs, customer portals, and more.

Seldon IQ
Customized enablement, workshops, and certifications.

Simplify the deployment, support for common design patterns (RAG, prompting, and memory) and lifecycle management of Generative AI (GenAI) applications and LLMs.
Includes
- Deployment with Standardized Prompting
- Agents and Function Calling
- Embeddings and Retrieval
- Memory and State Management
- Operational and Data Science Monitoring
- Benefit from Seldon's Ecosystem

Model Performance Metrics (MPM) Module enables data scientists and ML practitioners to optimize production classification & regression models with model quality insights.
Includes
- Comprehensive Metric Coverage
- Feedback Storage and Linking
- Time-Based Trend Analysis
- Model Quality Dashboards
- Benefit from Seldon's Ecosystem
Add powerful explainability tools to your production ML pipelines, including a wide range of algorithms to understand model predictions for tables, images, and text covering both classification and regression.
Includes
- Comprehensive Detection Coverage
- Pre-trained Models and Supported Datasets
- Model- and Context-Aware Detection
- Benefit from Seldon's Ecosystem
Add powerful explainability tools to your production ML pipelines, including a wide range of algorithms to understand model predictions for tables, images, and text covering both classification and regression.
Includes
- Comprehensive Explainability Coverage
- Storage and Portability
- Benefit from Seldon's Ecosystem
+Support and Modules
Our business is your success. Stay ahead with accelerator programs, certifications, hands-on support with our in-house experts for maximum innovation.
Simplify the deployment, support for common design patterns (RAG, prompting, and memory) and lifecycle management of Generative AI (GenAI) applications and LLMs.
Model Performance Metrics (MPM) Module enables data scientists and ML practitioners to optimize production classification & regression models with model quality insights.
Includes
Add powerful explainability tools to your production ML pipelines, including a wide range of algorithms to understand model predictions for tables, images, and text covering both classification and regression.
Add powerful explainability tools to your production ML pipelines, including a wide range of algorithms to understand model predictions for tables, images, and text covering both classification and regression.

Innovate Freely
Freedom to build and deploy ML your way, whether on-prem, in the cloud, or across hybrid stacks.
With support for traditional models, custom runtimes, and GenAI frameworks, Seldon fits your tech, your workflows, and your pace without vendor lock-in.

Learn Once, Apply Everywhere
Scale confidently with a unified deployment process that works across all models, from traditional ML to LLMs.
Seldon eliminates redundant workflows and custom containers, enabling your teams to launch faster, reduce errors, and scale ML consistently.

Zero Guesswork
Get real-time insights into every model, prediction, and data flow no matter how complex your ML architecture.
From centralized metric tracking to step-by-step prediction logs, Seldon empowers you to audit, debug, and optimize with complete transparency.

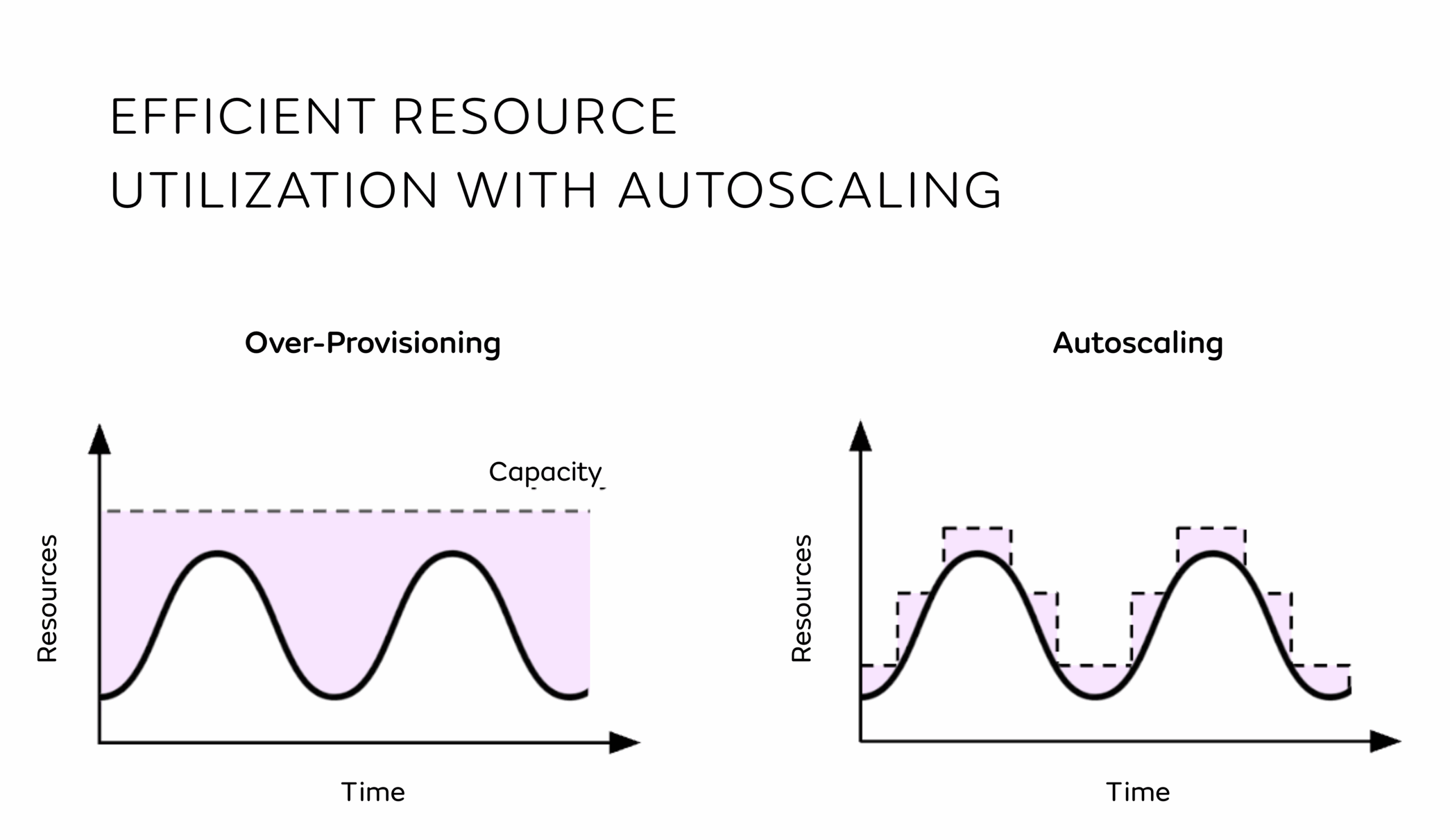
Efficient by Design
Modular framework scales dynamically with your needs, no overprovisioning, no unused compute.
Features like Multi-Model Serving and Overcommit help you do more with less, cutting infrastructure costs while boosting throughput.
Core 2 Architecture
Seldon Core 2 leverages a microservices-based architecture with two layers:
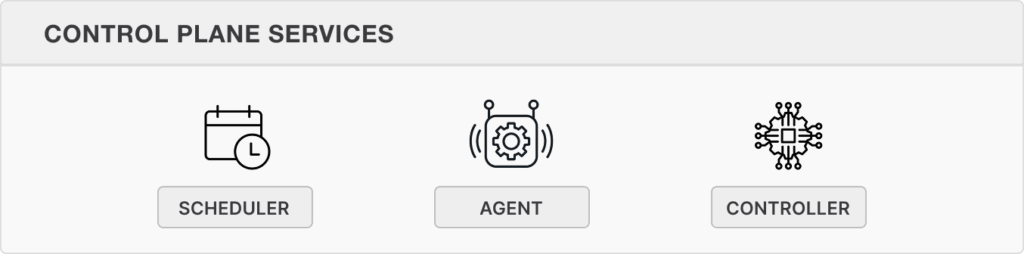
Manage inference servers, model loading, versioning, pipeline configurations, running experiments, and operational state to ensure resilience against infrastructure changes
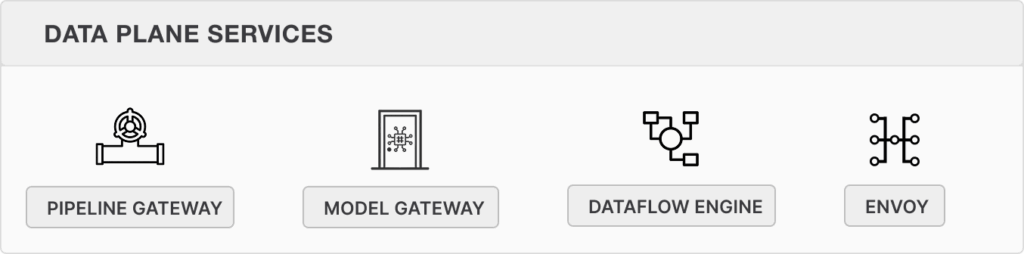
Handle real-time inference requests using REST and gRPC protocols with the Open Inference Protocol (OIP) and are powered by Envoy for intelligent routing
It also enables interoperability and integration with CI/CD and broader experimentation frameworks like MLflow by Databricks and Weights & Biases.
Download Core 2 Product Overview
Get Models into Production at Scale
Seldon Core is licensed under a Business Source License (BSL) In order to use Seldon Core in production you will need a commercial license by purchasing online or requesting an invoice.
Latest Articles

Stay Ahead in MLOps with our
Monthly Newsletter!
Join over 25,000 MLOps professionals with Seldon’s MLOps Monthly Newsletter. Opt out anytime with just one click.
✅ Thank you! Your email has been submitted.
Stay Ahead in MLOps with our
Monthly Newsletter!
✅ Thank you! Your email has been submitted.