Understand MLOps needs and how they arise through the MLOps Lifecycle. Apply this to better scope and tackle MLOps projects.
MLOps can be difficult for teams to get a grasp of. It is a new field and most teams tasked with MLOps projects are currently coming at it from a different background.
It is tempting to copy an approach from another project. But the needs of MLOps projects can vary greatly. What is needed is to understand the specific needs of each MLOps project. This requires understanding the types of MLOps needs and how they arise.
A Simplified MLOps Project
At the simpler end of the spectrum, an MLOps setup can closely resemble a mainstream DevOps lifecycle.
Traditional DevOps empowers the build-deploy-monitor lifecycle for software applications. An executable is built from source code, deployed to an environment and then monitored for any issues.
Training of a model can be thought of like building an executable. We’ll see later that it can also get more complex. But if the training process is simple then it can be handled as a traditional continuous integration build.
There are different deployment patterns for MLOps but let’s assume we have a real-time serving use case. Then we want to take the trained model and use it to make predictions via HTTP.
Trained models may be specific to the framework that they were trained on. A common approach to deployment is to use an off-the-shelf serving solution that can work for the framework. One open source serving solution that supports a range of frameworks is Seldon Core, a project I work on.
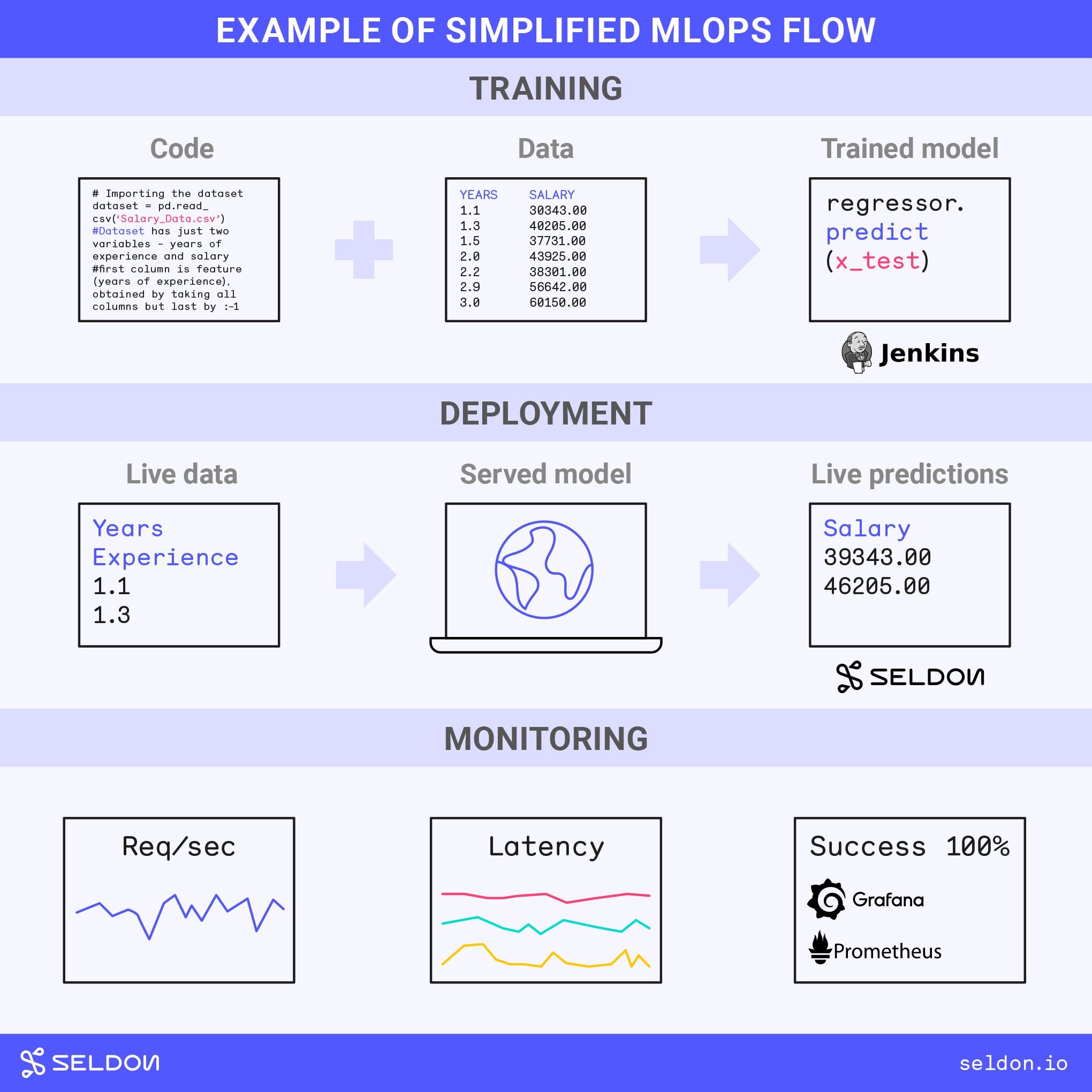
Image by Seldon. Shared under CC BY-SA 4.0
With mainstream DevOps the monitoring phase centres on looking for issues such as error codes or poor response times. For MLOps we also want to monitor for prediction quality.
A model is trained on a certain chosen dataset. That data may not match the live data perfectly. To ensure the model keeps performing well, we can monitor for key business or model metrics.
The above flow can be workable if the data is well-structured and predictable and there aren’t any additional governance needs. Otherwise we get into more complex MLOps needs.
An Advanced MLOps Lifecycle
Machine Learning is exploratory and data-driven. In essence it is about extracting patterns from data and reapplying those patterns to new data. If all goes well you get good predictions. The exploratory part is finding the right patterns for the data you intend to make predictions on.
When the data is not well-structured or predictable then the MLOps lifecycle can look very different to mainstream DevOps. Then we see a range of approaches come in that are specific to MLOps.
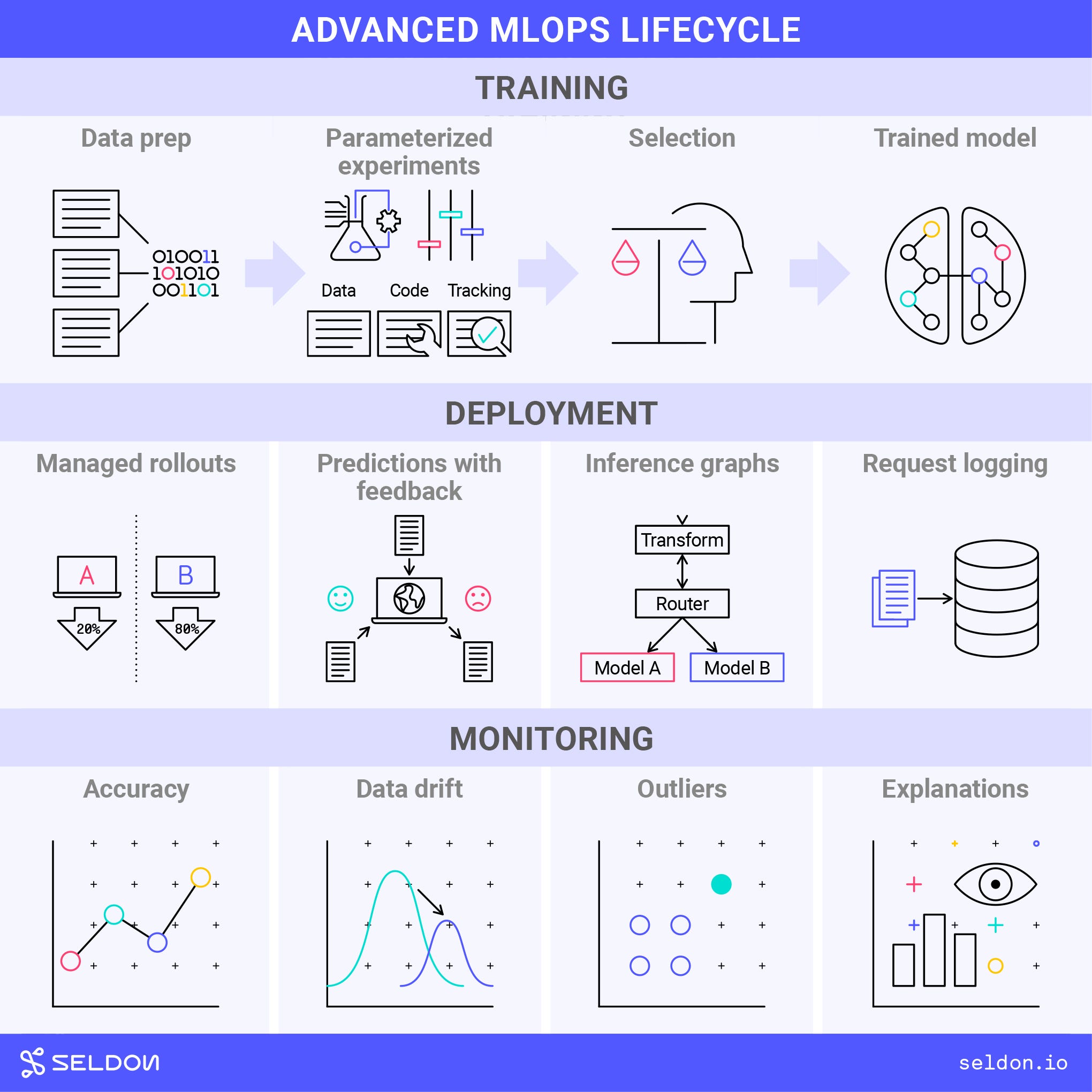
Image by Seldon. Shared under CC BY-SA 4.0
Let’s go through each of the phases in turn and the approaches that come into play. We’ll see how each MLOps need arises.
Training
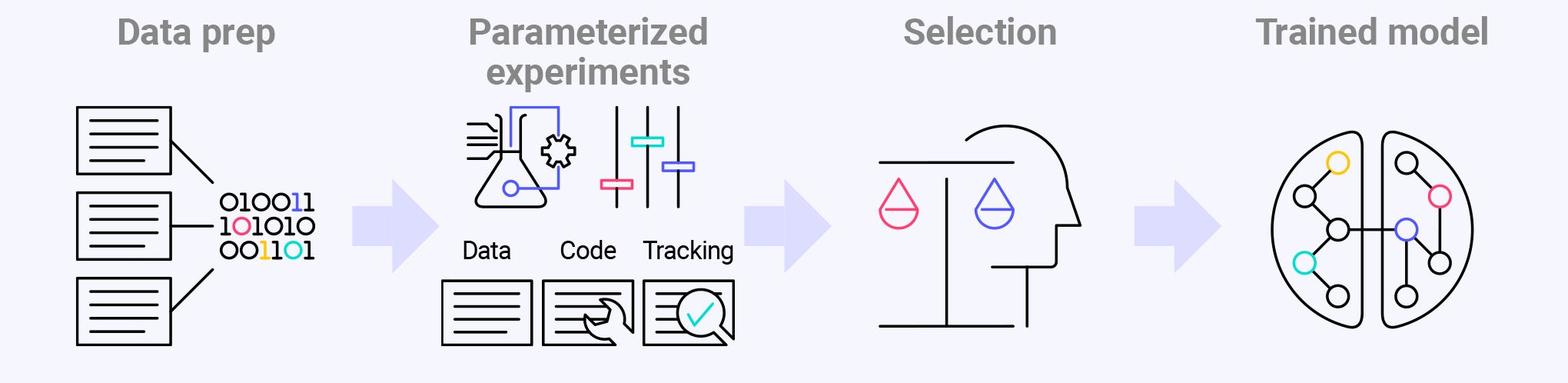
Image by Seldon. Shared under CC BY-SA 4.0
Training is about finding the best patterns to extract from training data. We encapsulate these patterns in models. Training runs have parameters that can be tweaked to result in different models. Encapsulating the best patterns in models is exploratory.
To explore parameters for the best models it makes sense to run multiple jobs in parallel. This is done in a hosted training environment running a specialist training platform. The best model for deployment then needs to be selected and packaged.
Data is a big part of why these platforms are run hosted rather than on a Data Scientist’s laptop. The volumes can be large. And data rarely starts ready for training models. That means a lot of preparation needs to be performed on it. This can take a lot of time and hardware resources. For governance and reproducibility reasons the preparation operations might also all need to be tracked.
Deployment
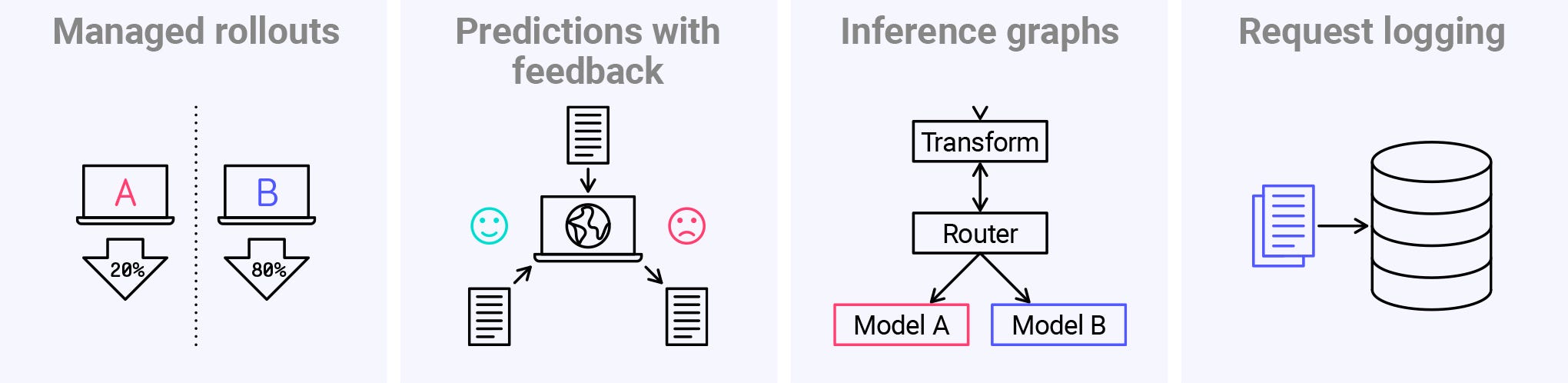
Image by Seldon. Shared under CC BY-SA 4.0
When we’ve selected a new model then we need to work out how to get it running. That means determining whether it’s really better than the version already running. It may have performed better on the training data but the live data could be different.
MLOps rollout strategies tend to be cautious. Traffic may be split between the new model and the old model and monitored for a while (using an A/B test or canary). Or the traffic may be duplicated so that the new model can receive requests but just have its responses tracked rather than used (a shadow deployment). Then the new model is only promoted when it has been shown to perform well.
We need to know a model is performing safely in order to promote it. This means deployment needs support from monitoring. We can also find that deployment may need to support a feedback mechanism for optimum monitoring. Sometimes a model makes predictions that turn out to be right or wrong e.g. whether a customer chose a recommendation. To make use of that we’d need a feedback mechanism.
An advanced case of splitting traffic for optimization is use of multi-armed bandits. With a bandit the traffic is split in a continuously-adjusting way. The model performing best gets most of the traffic and the others continue to get a small portion of traffic. This is handled by an algorithmic router in an inference graph. If the data changes later then a lesser-performing model may shift to becoming the dominant model.
Deployment can be intimately tied to monitoring. Deployment tools such Seldon therefore not only support deployment-phase features but also have integrations for the MLOps needs of the monitoring phase.
Monitoring
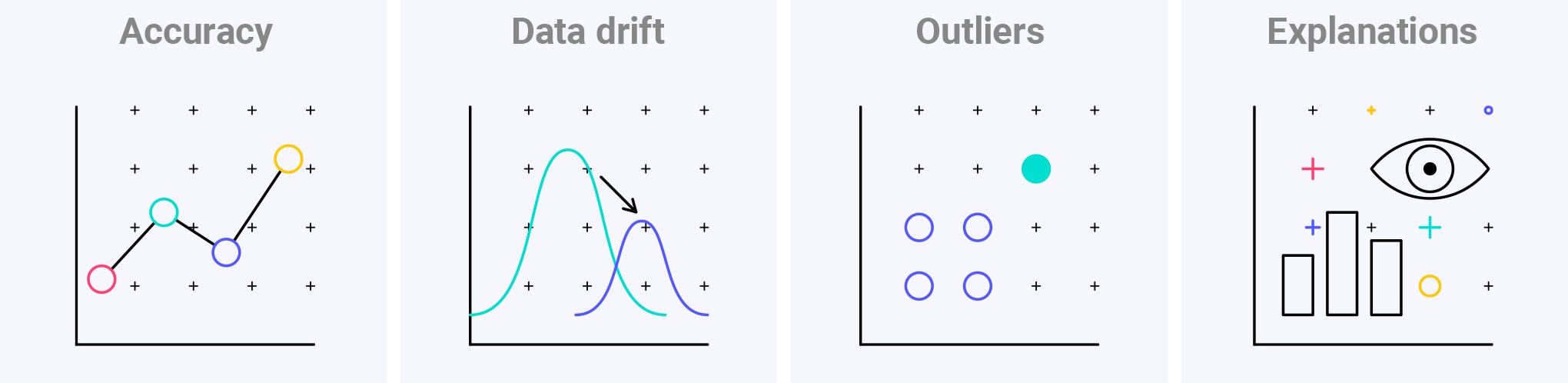
Image by Seldon. Shared under CC BY-SA 4.0
Monitoring for model accuracy is possible only if you have feedback. This is a good example of a monitoring feature needing a deployment-stage feature. In some cases live accuracy may be the key metric and in other cases a custom business metric may be more important. But these are only part of the monitoring picture.
The other side of ML monitoring is seeing why a model performs well or badly. That requires an insight into the data.
A top reason why model performance may drop is a change in the live data. If the data distribution shifts away from the training data then performance can drop. This is called data drift or concept drift.
Even if the overall distribution remains in line with the training data, some predictions may still be dramatically wrong. This could happen if some individual data points are outside of the distribution. These outliers can be damaging in cases where predictions need to be reliable across the board.
Fully understanding why a model made a certain prediction can require looking at how a model makes predictions and not just the input data. Explanation techniques can reveal the key patterns that a model is relying on for its predictions and show us which patterns applied to a particular case. Achieving this level of insight is a data science challenge in itself.
There are different approaches to achieving advanced monitoring. At Seldon we make heavy use of asynchronous logging of requests. Logged requests can then be fed into detector components to monitor for drift or outliers. Requests can also be stored for later analysis e.g. explanations.
Assessing MLOps Needs
It’s difficult to offer hard rules about what MLOps projects need. Parts of the lifecycle might be considered a nice-to-have for some projects (e.g. request logging). But for other projects that same element might be essential (e.g. compliance-focused projects). This suggests an approach that centres on asking the right questions.
MLOps Scoping Questions
Here is a sample set of questions to use to assess an MLOps project:
- Do we have the data and is it clean?
- How and how often will we get new iterations of the data and will it be clean?
- Do we need a training platform and does it need to be linked to CI?
- What ML framework is being used and what’s the easiest way to serve models for it?
- Does it look like a real-time serving use case or an offline/batch use case?
- Will the format of prediction requests be similar to the data format the model is trained on (check the raw form for reference)?
- Do we think the data could vary/shift?
- Do we expect to do online learning or to train offline?
- Do we expect to need to retrain the model due to data change and if so how quickly?
- Would outliers cause a problem?
- Do we need explainability?
Platforms vs Projects
Many organizations are not only looking at one-off MLOps projects. Many are looking to build a platform capability to cover a range of projects. Given how much MLOps projects can vary, this calls for a different set of questions.
- What are the range of use cases?
- Who will be responsible for deployment and what skills do they have?
- What tools are the team familiar with and what would they be comfortable using?
- What audit, compliance and reporting requirements do we have? Are there any high-compliance/high-risk use cases?
- How many teams and models will it have to scale to?
- Is there a product or set of products that could be a fit?
- What’s the budget, resources and skills available internally?
Advanced Platform Supporting Tools
Some platform use cases employ specialist MLOps tools that are not currently part of the mainstream for single project use-cases.
Model Registries
Image by Seldon. Shared under CC BY-SA 4.0
If you’re running lots of deployments of models then it becomes important to record which versions were deployed and when. This is needed to be able to go back to specific versions. Model registries help with this problem by providing ways to store and version models.
Feature Stores

Image by Seldon. Shared under CC BY-SA 4.0
In larger organizations multiple teams may be using the same raw data in different ways. Feature stores allow teams to drill into the raw data and see what preparations other teams have already performed on it. This can help reduce the need for teams to reinvent the wheel on data preparation.
Metadata Stores

Image by Seldon. Shared under CC BY-SA 4.0
For platform-level tools to offer insights about data going through models, it is important to know what type of data is in play. Text, image and tabular data are all very different for instance. Tracking this is the role of ML metadata. It’s early days for this space and Seldon is contributing the Kubeflow Model Management SIG to help advance metadata tooling.
Approaching MLOps Projects with the MLOps Lifecycle
There’s much to approaching MLOps projects that we’ve not covered here. We’ve not talked about estimation, scheduling or team composition. We’ve not even got very far into the tool landscape. Hopefully what we have achieved is to find our feet.
We’ve learnt to understand the MLOps lifecycle in terms of a set of needs. We’ve seen that ML is about taking patterns from data and reapplying those patterns. Data can be unpredictable and that can mean we have to be cautious about rollouts and that we have to monitor at the level of data and not just errors.
Once we understand the needs behind MLOps then we’re better placed to see how to leverage MLOps tools. We’re also better placed to ask the right questions in order to scope and approach MLOps projects