May we introduce you to our newest update, Seldon Core 2.9! This release is packed with updates that make deploying and scaling ML easier and more flexible than ever, including improvements to autoscaling, support for streamed results for GenAI models, and various other usability improvements described in more detail below.
Also tested alongside a new upgraded release of MLServer (1.7), this release includes support for Python 3.11 and 3.12, support for new data-types, as well as several new usability improvements and fixes that include contributions from the open source community. Whether you’re running large-scale inference services or exploring LLM use cases, these updates to our products have something for you!
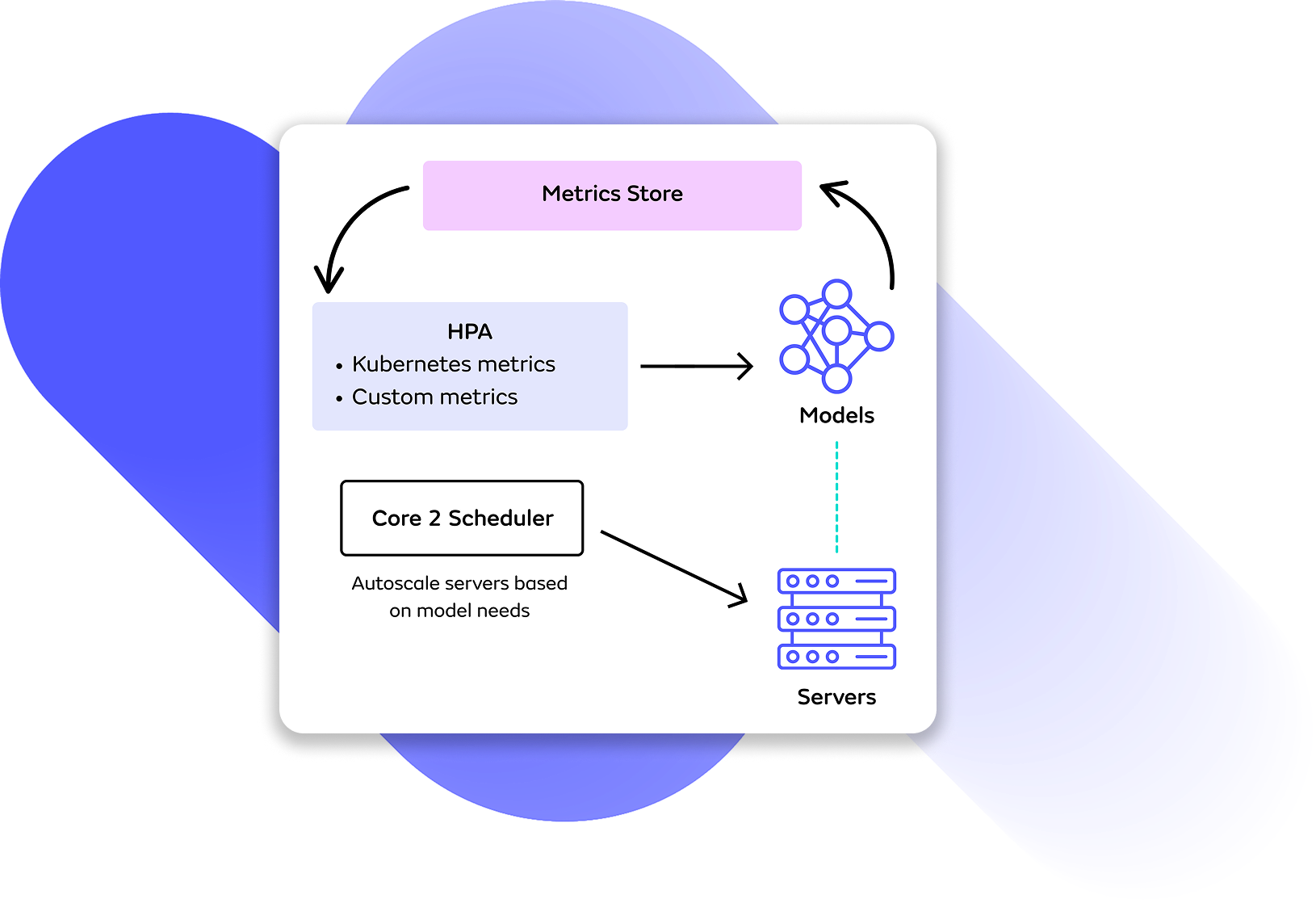
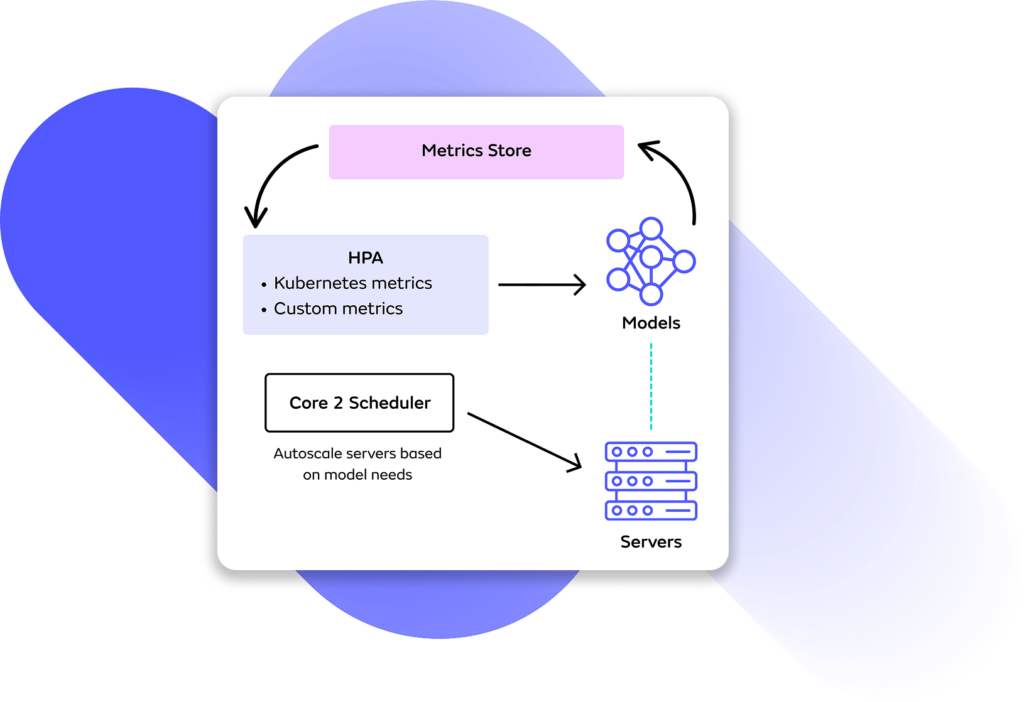
Smarter Autoscaling
Core 2.9 provides a new, simpler implementation of autoscaling that unlocks enhanced configurability and cost-savings. Users can now set up autoscaling of models using HPA, and Seldon will autoscale your server replicas automatically. This implementation allows for more configurability by expanding the metrics you can use to define scaling logic as you can now use Kubernetes-native or custom metrics to scale your workloads. It also supports autoscaling for Multi-Model Serving setups where you can consolidate multiple models on shared servers to save cost.
Learn more about the new autoscaling workflow in the docs →
Response Streaming
You can now stream inference responses for GenAI models to return results token-by-token, both via REST and gRPC. This is perfect for any real-time, low-latency GenAI applications whether they be chatbots or coding copilots.
Revamped Documentation
The docs have been migrated to a new platform, and overhauled to improve discoverability. We’ve also added new content to provide enhanced support on common workflows such as the installation process →
Usability and Configurability Improvements
Partial Scheduling
Core 2.9 introduces improved handling of partially available models. Instead of waiting for all replicas of a model to be ready, Seldon can now schedule as many as possible based on resource availability. That means Models can still serve traffic even if only some of the model replicas are deployed, resulting in smoother autoscaling behavior, especially in resource-constrained environments. As part of this work, we’ve also added new model status fields that show how many replicas are currently available, in order to clarify the state of models as they change with elastic scaling.
Configuration via Helm
You can now configure a wide range of settings using Helm, including:
- Min/max replicas for MLServer and Triton
- Enabling/disabling autoscaling features
- PersistentVolumeClaim (PVC) retention policies
- Log levels for all components, including Envoy
CRD Updates
Seldon’s Model Custom Resource Definition (CRD) now supports:
- A new spec.llm field to better support prompt-based LLM deployments
- A status field for availableReplicas to power the new partial scheduling logic (as described above)
- Full backward compatibility, so you can upgrade with confidence
Bug Fixes
The following bugs identified by our users and customers have been fixed as part of the 2.9 release:
- 503 errors during model rollouts caused by out-of-order routing updates
- Prometheus metrics now correctly use model names, not experiment names
- Kafka-based error propagation for issues in model gateway
Pod spec overrides for seldon-scheduler now apply as expected
MLServer 1.7
MLServer 1.7 brings a range of usability enhancements and bug fixes contributed by both Seldon and our open-source community. Notably, it now includes support for Python 3.11 and 3.12, an improvement led by a community contribution. We’ve also introduced greater configurability for the inference pool used by models, helping you maintain performance standards when deploying models with varying resource requirements on shared infrastructure.
The release also expands our MLflow integration by supporting new data types provided by the MLflow runtime (Array, Map, Object, and Any) further broadening its flexibility, along with several bug fixes and dependency upgrades bundled in this version.
