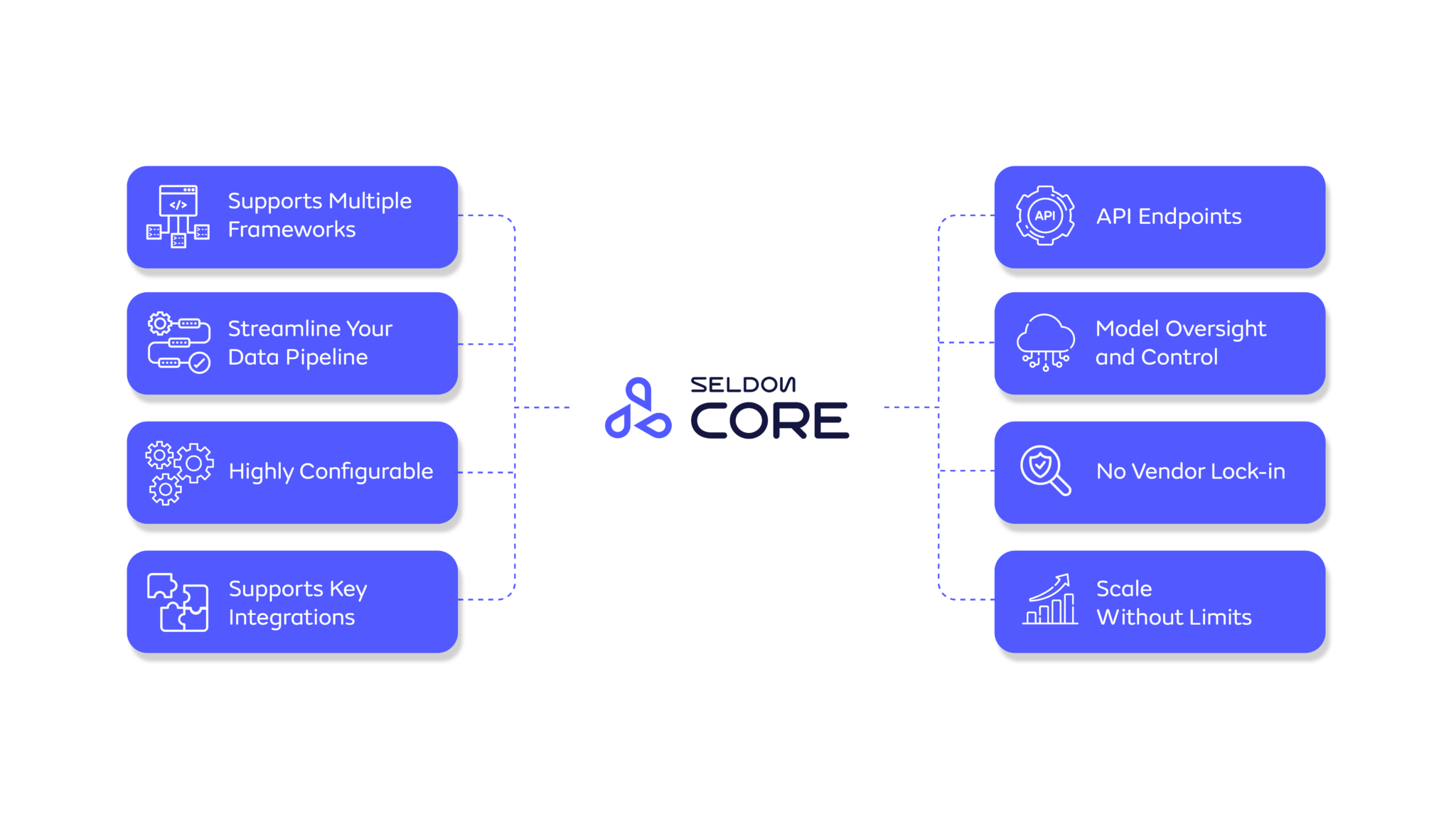
Core 2 is a modular framework with a data-centric approach, designed to help businesses harness the growing complexities of real-time deployment and monitoring.
Trusted by the Worlds Most Innovative ML and AI Teams
9.5+
Million models installed across a range of model types from the most popular libraries to custom developments
4.8
GitHub rating and trusted by ML and AI teams worldwide for better machine learning deployment and monitoring
85%
Increase in productivity through enablement of better workflows and more efficient use of resources
Find Clarity in the Complex
Seldon’s data-centric approach and modular design ensures accurate, adaptable data and fosters confidence in models in production at scale.
Freedom to Innovate Without Restrictions
Seldon offers a platform- and integration-agnostic framework, enabling seamless on-premise or cloud deployments for any model or purpose regardless of your tech stack requirements.
Support of multiple runtimes that allows your team to benefit from a broad range of pre-trained models. We support Triton via ONNX, PyTorch, TensorFlow, and TensorRT, MLFlow, Scikit, XGBoost, Hugging Face, and custom.
Seamless Integrations: Connect with CI/CD, automation, and various ML tools (cloud, in-house, third-party).
Flexible & Standardized Deployment: Deployable on GCP, Azure, AWS, RedHat OpenShift, or on-premise, and more. Deploy traditional ML, custom models, or GenAI—whether as single models or complex applications—using a consistent workflow. Mix models and components with support for both custom and out-of-the-box runtimes.
Streamlined Operations
No tireless search for models and information while creating more opportunity to scale with less overhead, and reduces risk of investment with the ability to identify problems and opportunity faster with features like:
Standardized Inference Protocol – Supports only model servers following the Open API Inference Protocol for consistent request and response handling.
Built-in Model Servers – Includes MLServer and Triton to support all major ML frameworks, with easy customization for input/output handling.
Manifest-Based Configuration – Manage models and workflows with a simple file, avoiding the complexity of function-based coding.
Optimized Autoscaling – Standardized CPU utilization metrics enable seamless scaling across models, eliminating hardware-specific dependencies.
Enables Enhanced Observability
Enables visibility into ML systems, covering data pipelines, models, and deployments through features like:
Real-Time Insights: Track, audit, and monitor models with transparency into data and decision-making.
Exposed, Flexible Metrics: Aggregate operational, data science, and custom metrics for tailored insights.
Interconnected Inference Logic: Enable richer, more dynamic insights by ensuring inference logic seamlessly connects across modules.
Programmatic Inference Graph – Define component relationships, create manifest files, and connect multiple components in a single manifest.
Real-Time Data Streaming – Stream, store, and use data efficiently with a data-centric approach (Kafka integration).
Modular Framework for More Optimized Infrastructure
Dynamically adjust infrastructure based on actual demand, minimizing waste, reducing costs, and optimizing performance with features like:
Experimentation-Driven Efficiency – Improve model quality while optimizing cost and resources through experimentation features.
Interconnected Inference Logic – Ensures data flows seamlessly across modules for richer, dynamic insights.
Separation of Concerns – Data-centric architecture maintains modular independence, simplifying updates and scalability.
Smart Scaling & Autoscaling – Scale models and servers based on workload demand, with adaptive batching in MLServer for fine-tuned efficiency.
Multi-Model Serving (MMS) – Deploy multiple models efficiently on fewer servers, optimizing infrastructure and costs.
Overcommit for Smarter Memory Use – Uses an LRU caching mechanism to prioritize frequently accessed models, reducing memory constraints and enabling large-scale deployments.
Seldon Core 2 was developed to put data at the center of your machine learning deployments for more enhanced observability leading to better understanding, trust, and iteration of current and future projects.
Seldon Core is licensed under a Business Source License (BSL) In order to use Seldon Core in production you will need a commercial license by purchasing online or requesting an invoice.
Our Licensing FAQs
A comprehensive list of everything you need to know about how to get the most out of Seldon Core.
Join over 25,000 MLOps professionals with Seldon’s MLOps Monthly Newsletter—your source for industry insights, practical tips, and cutting-edge innovations to keep you informed and inspired. You can opt out anytime with just one click.
Email Signup Form
✅ Thank you! Your email has been submitted.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok